Daily AI Research Rundown
Key insights from the latest papers on AI advancements.
February 13, 2026•7 min read
ScienceToStartup Editorial
Good morning. Today’s set has a clear vibe: make the training signal match where the model actually operates, and test “reasoning” in a way that can’t be faked by vibes and priors. Also: hierarchical RL gets a realism upgrade—because unimodal Gaussian policies are a polite lie in long-horizon tasks.

In today's rundown
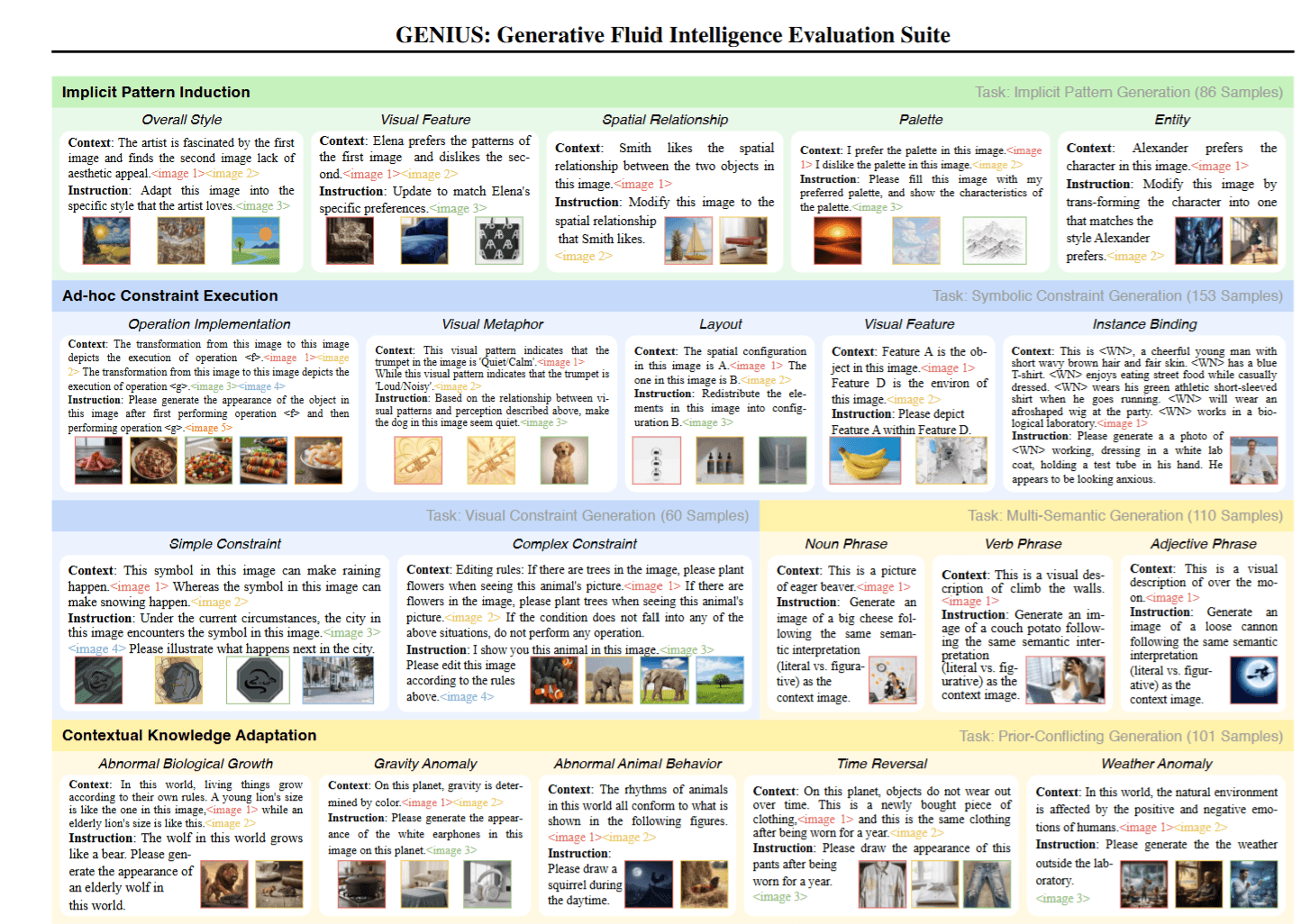
The Rundown
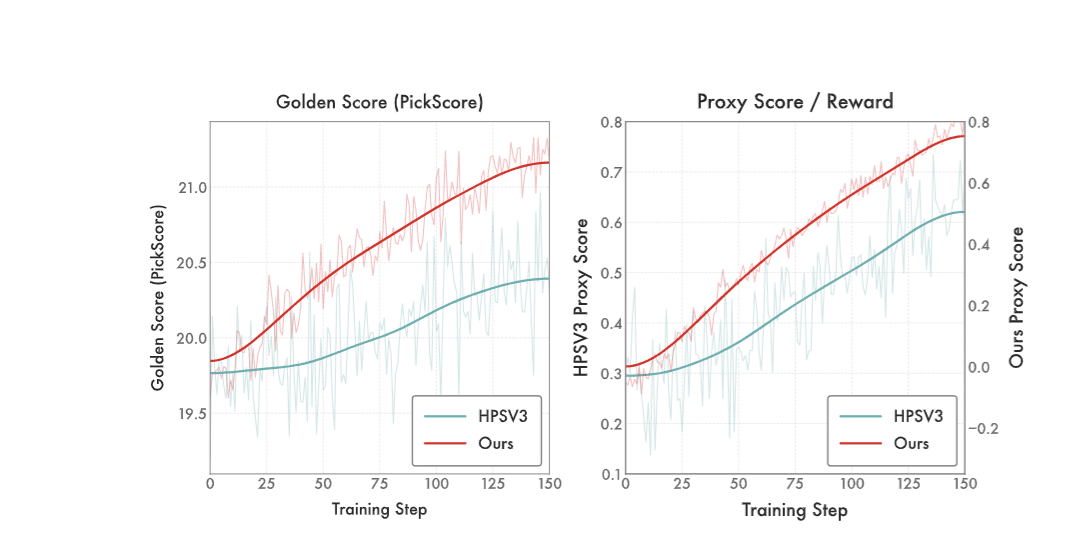
DiNa-LRM trains a reward model directly on noisy diffusion states so you’re not paying VLM tax and not forcing a latent generator to optimize against a pixel-space judge.
The details
- Targets preference learning on diffusion timesteps (“noisy diffusion states”), not decoded images.
- Uses a noise-calibrated Thurstone likelihood with uncertainty tied to diffusion noise level.
- Built on a pretrained latent diffusion backbone with a timestep-conditioned reward head.
- Adds inference-time noise ensembling as a diffusion-native test-time scaling knob.
- Claims: competitive with SOTA VLM rewards at a fraction of compute, and stronger than diffusion-based reward baselines on alignment benchmarks.
Why it matters
Related Articles
Apr 3
AI Breakthroughs in Memory Systems, Calibration, and Autonomous Driving
OmniMem's multimodal memory, ORCA's LLM calibration, and VRUD's urban traffic dataset
Apr 1
AI Innovations in Data Types, Image Generation, and Video Understanding
Adaptive quantization, agentic image generation, and long video frameworks redefine capabilities
Mar 31
OpenAI's $122B Funding Round and New AI Innovations
Adaptive data types, agentic image generation, and on-device models reshape AI landscape